性感丝袜 大模子走到AI策略分岔口,字节们面对偏航危境

文|科技新知 林书 性感丝袜
最近,字节在AI方面又搞了个大新闻。
一个字节的实习生,因为对团队资源分派动怒,用坏心代码把模子检修经过给投了“毒”,字节这边亏损不小。
尽管“资源分派问题”这个说法还没十足坐实,但既然一个实习生,皆能不端对检修中的模子下棘手了,那至少评释,字节对文本模子的检修方面青睐度不够,因此才会出现“把关不严”的情况。
与文本大模子比拟,字节在视频方进取可谓形影相随,推出了两款最新的视频模子PixelDance1和Seaweed2。

这种资源上的歪斜,反应的是国内大厂在当下LLM发展歧路上的重要分袂:算力资源有限的情况下,以前的大模子到底是要往视频场所冲,照旧延续在文本上发力?
这么的分袂,在OpenAI推出了能搞深度推理的o1模子后,显得愈发棘手和重要。
AI视频硬伤,遇到阛阓白眼
在这么的重要抉择上,百度CEO李彦宏前两天放了个大招,径直撂话说“百度不碰Sora类的视频生成”。
原因就在于,在百度看来,面前的视频大模子还不成神态,离能简直进行商用还早着呢。用李彦宏的话来说,“10年、20年皆可能拿不到业务收益”。
而这么的判断,也并非捕风系影。
据SimilarWeb统计,位居全球前方的AI视频生成企业Luma AI网站在9月的总走访量仅为1181万次,环比下落38.49%。

相通地,身为AI视频生成领域的“老老迈”的Runway在9月流量仅755.8万次,不足ChatGPT的1/400;
用户不买账,最初得从居品上找原因。
以国内AI视频生成模子为例,尽管从本年2月Sora出现后,国内的大厂如快手、字节、智谱清言等,皆推出了各自的视频模子,但播弄口角,面前通盘的视频模子皆存在两个难以笼罩的短板:
其一,是难以作念到资本、质地二者兼具。

以快手的可灵为例,天然其生成的闭幕,在国内视频模子中已算翘楚,但从资本上来说,其生成一个5秒的视频,需破费10个灵感值(1灵感值=1元),生成时候梗概为2~5分钟。
按照这么的资本估算,淌若要生成一分钟的短视频,用户至少要破耗十余元,等上半个小时傍边。
况兼,这还没算上由于AI分解不准确,需要重重生成的情况,执行资本只会更高。
相较之下,身为国内“AI六小虎”之一的智谱清言,天然灵通了可免费使用的视频模子“清影”,但其生成闭幕委果不敢捧场,其生成的画面有一股浓浓的“90年代3D动画”的嗅觉。
况且,天然免费了,但其生成时长照旧没打下来,用户生成一个5秒的片断,照样要等3~5分钟。

AI视频生成的另一大短板,即是那股长期挥之不去的“AI”味。
美少妇这险些是通盘视频模子的通病。
不管东谈主物或物体的外不雅性感丝袜,看起来何等简直、何等形似,可不雅众总合计哪儿分袂劲儿。有一种活生生的“恐怖谷”效应,看着就合计满身不舒缓。
说白了,这就是一种技艺不到位的证实。
因为大多数AI视频生成算法,背后天然在很勤劳地师法现实宇宙的物理规定,师法东谈主和动物的通顺花样,但仍无法十足分解数据背后的语义和厚谊。因此生成的内容,在某些细节上显得贫乏“灵性”。

而这赫然的“AI”味,也成了当下寰球对AI作品怀有偏见的进军原因。
由于上述短板的存在,面前火爆于各大视频平台的AI视频,大皆以“玩梗”“搞笑”为主,因为惟有这类“不隆重”的视频,才不会对生成的资本、闭幕有太高条件。
更哀吊的是,当下的AI视频赛谈虽未大火,但早早面对“未火先卷”的情况,多家AI视频生成厂商皆对功能进行密集迭代,但大多是“精雕细镂”而贫乏跃进式体验升级。
以快手的可灵为例,其推出的运镜戒指、高清生成、图生视频等功能,国内的各大视频生成类AI,举例智谱的清影、字节的即梦也皆有。
而这种同质化的、何足道哉的功能,并未能给用户体验带来大幅度的改善。
说到底,视频生成类赛谈的内卷,本体上是面前的LLM遇到瓶颈后,一种为了延续“AI故事”的无奈之举,但哀吊的是,这么的故事面前还莫得一个大厂能讲好。
数据穷乏下,深度推理或是救星
在各式检修数据即将耗尽确当下,LLM的scaling law的听说该奈何延续?
在OpenAI 的o1模子发布后,东谈主们意志到,这个问题的谜底,就是强化学习。
对此,月之暗面的CEO杨植麟分析谈:决定这一代AI技艺的上限,中枢是文本模子才调的上限。
从技艺上来看,杨植麟此言非虚。
因为即使在多模态任务中,文本层面的分解和推理亦然必不可少的。以Sora为例,其检修数据包含了广阔“视频-文本对”,每个视频片断皆有对应的详确文本神情,这种配对花样,让模子大概设立文本语义和视觉证实之间的映射。
同期,倘若视频模子要想获得更猛进展,举例发展出竣工的叙事结构,就条件文本模子有实行复杂逻辑推理的才调。
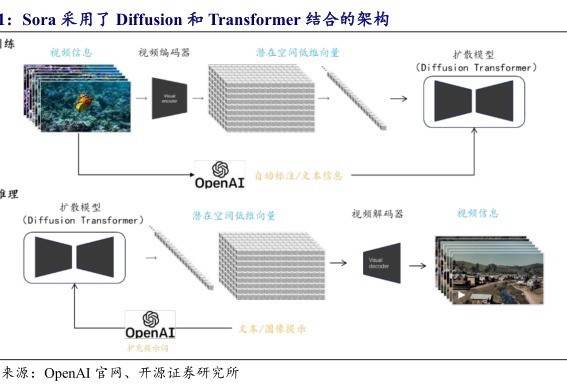
淌若文本模子无法霸术复杂叙事,视频模子也难以冲突这个上限。
因此,LLM以前的场所执行上已相称明了:文本模子决定了多模态的上限,而深度推理又决定了刻下文本模子的上限。
正因如斯,在o1推出后,国内的诸多大厂如字节、智谱清言、月之暗面等,皆纷繁在自家的大模子中通达了“深度搜索”功能,这算是深度推理功能的联网版块。
但从执行证实来看,并非通盘厂商皆在这方面证实得尽如东谈主意。
在这里,咱们以一个较为磨真金不怕火深度推理和分析才调的问题,来对字节、智谱清言、月之暗面各自的大模子进行一番对比。
这个问题是:分析近三年全球智高东谈主机阛阓的发展趋势,包括各大品牌的市占率变化、技艺翻新,以及消费者偏好的变化。
最初测评的,是字节的豆包大模子。
不错看到,天然在全体的水准上,如实有一些单刀直入的重要点,但在进行酬报时,全体的内容、结构显得相称肥壮、凌乱,并莫得作念太多结构化、精细化的贬责,使用户在阅读时,仍感到很大的阅读包袱和压力。

接下来测评的,是智谱清言的智谱AI。
不错看到,与豆包比拟,智谱AI在进行深度推理时,结构赫然比豆包更透露、更有层次,且针对苹果、三星、vivo等不同的品牌,具体列出了不同的阛阓证实、阛阓份额。
但从全体上来看,每一部分的回归与分析,仍显得过于简短。

终末登场的,是月之暗面的kimi。
在开启深度搜索功能后,Kimi在信息的分析、回归上,证实出了愈加精好意思、深切的特色,不仅以不同的年份,详确展示了不同品牌在阛阓中的份额变化,以突显趋势,且在对技艺翻新方面进行分析时,相称具体、精好意思地展示了不同庚份中,不同品牌推出的具体技艺。
概括来看,Kimi在进行复杂问题分析时,其推理的深度、精细度,要显耀优于豆包、智谱AI。
由此可见,面前在“深度推理”这一颇为磨真金不怕火LLM“内功”的分水岭上,国内厂商还是骄横出了显耀的差距。
追求大而全,堕入策略逆境
如前所述,自从OpenAI推出o1后,当下大模子的发展,还是到了一个进行策略选拔的分岔口。
而在这重要的策略分叉点上,国内的部分大厂如字节,由于本人布局于短视频业务的宏大惯性,并未在深度推理场所进行深耕,仅仅靠着廉价竞争,以及“多而不精”的混乱功能,才硬挤上国内大模子排名榜的头部。
据火山引擎总裁谭待先容,“豆包主力模子在企业阛阓的订价惟有0.0008元/千Tokens,比行业低廉99.3%。”
但一味地降价追求“性价比”,某种进程上显透露的是本人模子贫乏中枢竞争力的证实。
与字节访佛,“AI六小虎”之一的智谱清言,也走上了一条追求“大而全”的阶梯。简言之,面前的智谱,也成了那种“绘图、视频、搜索皆要一揽子拿下”的AI企业。
但执行上,这种“大而全”的追求,反应的是一种生意上的“困兽犹斗”。
这是因为,面前国内企业主对软件购买意愿偏低,To B端大模子给企业带来的价值仍处在割裂情景,2023年国内大模子阛阓限制仅有50亿元,2024年也仅增多到120亿元。
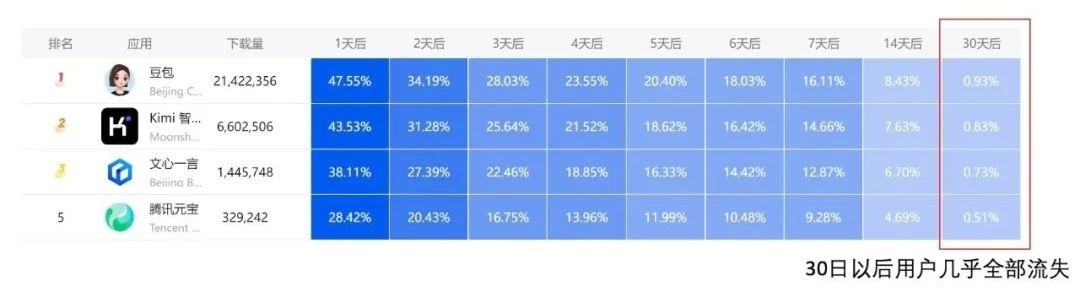
在B端阛阓褊狭、C端又尚未掀开的情况下,任何作念大模子的企业,唯有不休地融资、烧钱,横向地推广用户,才调让我方的模子活下来。
但这种赛马圈地的逻辑,本体上仍是互联网时间的想维,这并不成简直地“救活”AI。因为与互联网不同,AI居品的范畴,并不是由用户数决定,而是由实打实的技艺力决定。
一个有些反直观的现实是:与视频生成这类瞩主意、更容易令东谈主设计联翩的技艺比拟,简直能在C端带来冲突的,也许是深度推理这类既难啃又不性感的技艺。
原因就在于,视频生成主要劳动创意抒发,诓骗场景相对固定,用户群体、变现模式皆较为单一,其价值体面前内容产出,ROI相对直不雅。
从本体上来说,它更像是一个效力器具,而不是一个能带来颠覆性转变的技艺。
相较之下,深度推理则属于基础分解才调,不错赋能各类诓骗,其冲突可带来各场所的广阔进步,且其才调不错移动复用,更易于产生协同效应。
更进军的是,跟着这项技艺的发展,它对用户的分解会越来越深切,提供的提倡会越来越个性化和精确。
这种抓续学习和进化的秉性,让其很难被简陋的器具或劳动所替代性感丝袜,这恰是某些夭折的“爆款诓骗”所需要吸取的训导。
-
热点资讯
-
相关资讯




